Upload a screenshot to ChatGPT or your local favorite model and ask it to convert it to code. The layout comes back surprisingly well. The spacing is reasonable. The hierarchy makes sense. Then you look at the colors.
The button in the design is #E8453C. The model gives you #C94A3E. Close enough to feel plausible, wrong enough to fail a design review. So you do what everyone does — you prompt harder. “Pay close attention to exact hex values.” “Be precise with colors.” Maybe you even throw in “use a color picker” — as if the model has one (some do, as a tool — on the inferencing level).
It doesn’t help. It never helps. And once I understood why, I couldn’t stop thinking about it.

Millions of hex codes later
I spent months trying to solve this from the language model side. Built synthetic datasets — millions of hex codes, color palettes, RGB triplets, curated design combinations — and fine-tuned models on them. Llama 2, among others. Burned through compute hours on NVIDIA hardware, training models to reason about color.
And they could — in text. The fine-tuned models recited color theory, converted between color spaces, and told you that #E8453C is a warm red with moderate saturation. In a text-only conversation, they were genuinely impressive. The moment an image entered the pipeline, none of it mattered.
Because under the hood, every one of those fine-tuned models still ran the image through the same vision encoder — and the encoder still discarded the information the language model needed. The custom weights, the millions of training examples, the careful dataset curation — all of it was downstream of the bottleneck.
I was teaching the model advanced vocabulary of colors while handing it a textbook with pages ripped out.
That’s when the actual problem clicked. The bottleneck isn’t in the language model’s understanding of color. It’s in the vision encoder’s representation of it. And no amount of fine-tuning on the language side can fix what the vision side already threw away.

What patching discards
Most multimodal models process images through a vision encoder — typically Vision Transformer–based — that splits the image into fixed patches, commonly 14×14 or 16×16 pixels. Each patch is projected into an embedding vector and processed through attention layers. This is the right tradeoff for general vision. The encoder prioritizes structure and spatial relationships over exact pixel fidelity. It's excellent for scene understanding, spatial reasoning, and object recognition.
But it means color information is sacrificed by design, not by accident. A button that’s #E8453C in your Figma export becomes a statistical summary of the patch containing it. The embedding captures “reddish region, medium brightness” — enough for scene understanding, not enough for color reproduction. That’s what the language model receives. It then generates a hex value from that approximation — sometimes close, often not.
This isn’t a reasoning failure. The color information was destroyed during patch tokenization. It’s irreversible. No prompt can recover what the encoder threw away.
The gap between models confirms this. It's small — this isn't one model being bad at color... It's a structural limitation across the board. Vision encoders remain relatively small compared to the language models they feed. While language models scale into the tens or hundreds of billions of parameters, the visual perception layer is far more constrained. The bottleneck sits on the vision side, yet most scaling efforts have focused on the language model.

The pixel-level dream
After months of fine-tuning and the realization that the bottleneck was in the vision encoder — not the language model — the obvious next thought was: what if we just built a better one? What if the vision encoder just… kept the pixels? Preserve the color. Build an encoder that keeps everything.
The problem is compute. The entire ecosystem is optimized around reducing tokens, not increasing them. At high resolutions, vision encoder latency becomes the dominant bottleneck, and the cost scales aggressively with token count in the attention layers. Even where larger or improved encoders exist — InternVL’s 6B-parameter vision encoder or newer encoders like SigLIP 2 — the tradeoff is significant: more compute, more latency, and still patch-based. These models are better at understanding what’s in the image — richer semantics, stronger segmentation, improved OCR — but the fundamental patching operation still compresses pixel-level color into embeddings. The field is building token compression, aggressive pruning, and hybrid architectures — all to get the visual token count down. Going the other direction, toward pixel-level color preservation, would blow up inference cost for a property that most use cases don’t critically need.
For a daily-use pipeline — screenshot-to-code, a simple inference call — forking or rebuilding the vision encoder to preserve color fidelity doesn’t make sense. The entire industry is fighting to balance token economy and compute cost. You don’t rebuild the encoder — you supplement what it misses, at the right cost.
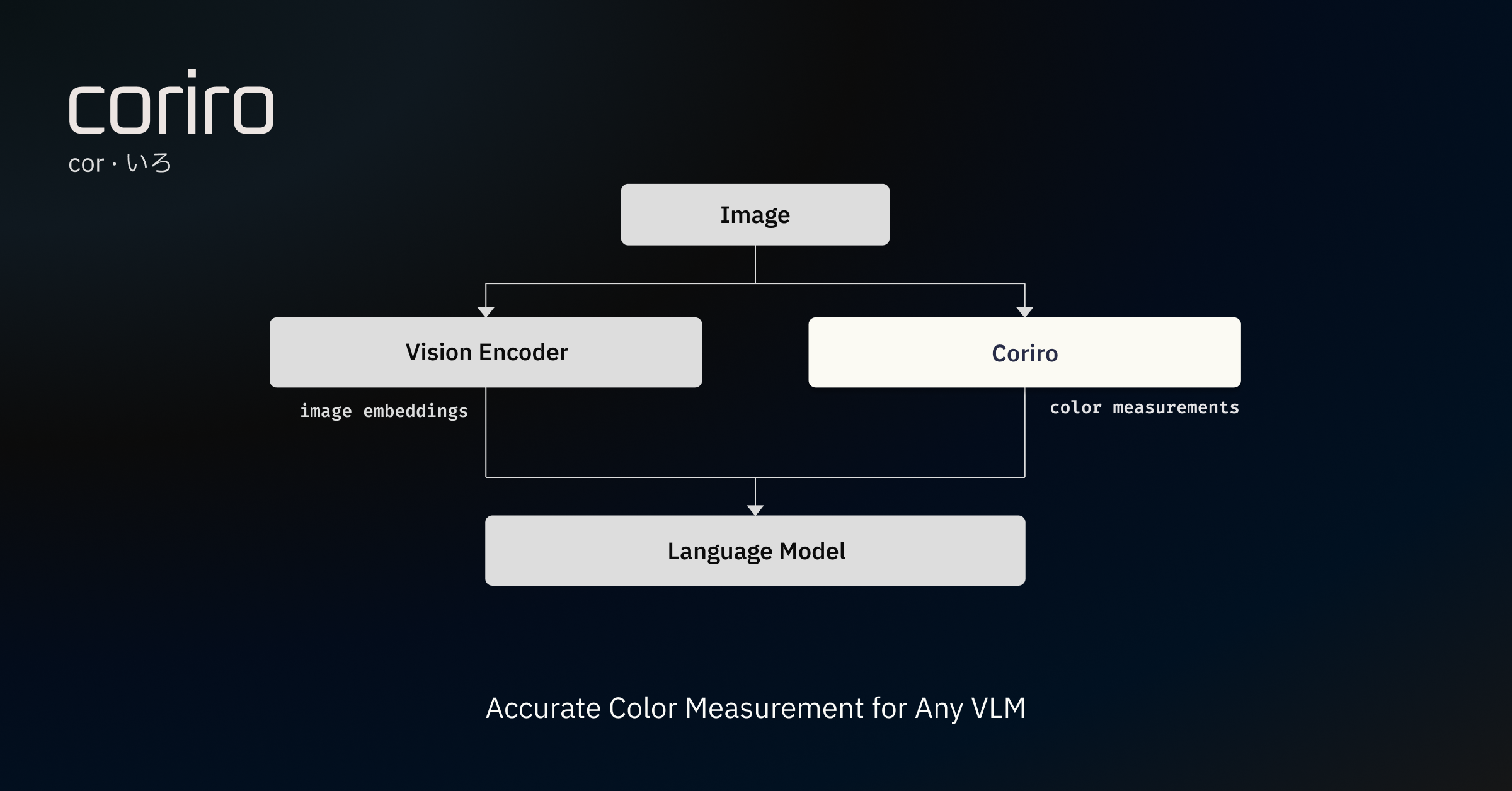
The sidecar
Measure the actual pixels — the way a color picker would — and pass the results as structured text alongside the image. Text is the channel where language models are already precise. They can reason about #E8453C with perfect fidelity when they receive it as a string. The problem was never reasoning; it was perception.
The first version was a 200-line script that dumped dominant colors into a prompt. It worked well enough to prove the idea — the model started nailing hex values it had been guessing at — and badly enough to demand a real architecture. What emerged is Coriro: a color measurement runtime that sits outside the model, measures the actual pixels, merges near-identical colors using perceptual distance thresholds, and hands the pipeline a structured palette instead of making the model guess. JSON, XML, natural language — whatever the pipeline consumes.
The model still sees the image. It still gets layout, hierarchy, semantics, and context from the vision encoder. But for color, it references measured values instead of guessing. Remove Coriro, and the pipeline runs exactly as before.
Most people will never need this. Color accuracy doesn’t matter when you’re asking a model to describe a photo or summarize a chart. “Reddish” is fine. But when color is the signal — screenshot-to-code, design-system compliance, product color matching, accessibility contrast auditing — “close enough” fails silently. The generated code looks right until you compare it to the design file. The contrast check passes until you measure rendered pixels instead of trusting the DOM.
These are niche problems. But if you’re in the niche, they’re the whole problem.
The closed world
One design decision I’m particularly attached to: if a color isn’t in Coriro’s output, it’s below the measurement threshold. Omission is signal, not oversight. The output includes explicit metadata — coverage thresholds, ΔE collapse distance, palette cap — so the receiving model knows the palette is authoritative. No gaps to fill with vision-inferred guesses.
That button? #E8453C. With Coriro in the pipeline, the model gets the measured hex as structured data before it generates a single line of code. It doesn’t have to guess. The measured value is already there: #E8453C.
That’s the whole system.
pip install coriro